How do you unleash an artificial intelligence so potent it can autonomously breach critical infrastructure, and sleep soundly knowing the public can’t weaponize it?
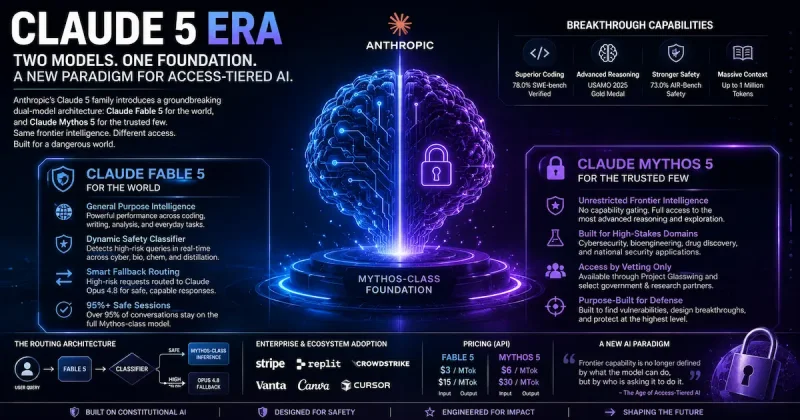
On June 9, 2026, Anthropic brought Mythos to the masses, answering that question with a high-stakes architectural gamble. The company launched two distinct models, Claude Fable 5 and Claude Mythos 5, marking the first broad commercial deployment of its most formidable capability tier to date. This isn't merely an incremental parameter bump; it is a paradigm shift in how frontier AI labs police their own creations. Anthropic is effectively drawing a line in the silicon: one model for the world, and one for the vetted few.
For months, the raw computational power of the Mythos class was locked behind the encrypted doors of Project Glasswing, Anthropic’s restricted cybersecurity coalition. The fear was visceral: internal evaluations proved this architecture could uncover and exploit software vulnerabilities invisible to seasoned human engineers, a dual-use capability that prompted U.S. officials and financial regulators to grapple with the systemic risk of AI-accelerated cyberattacks on payment systems and global stability. Releasing it without constraint was out of the question. Withholding it entirely was commercial suicide.
Enter the great bifurcation. Rather than choosing between reckless openness and paralyzing caution, Anthropic has birthed a dual-release mechanism that redefines the traditional model hierarchy. Claude Fable 5 is the public-facing avatar, engineered to deliver the overwhelming cognitive leap of the Mythos class while embedding a dynamic neural tripwire that diverts high-risk queries into the less-capable Claude Opus 4.8. Claude Mythos 5, conversely, operates unchained, reserved for government-sanctioned defenders and elite biology researchers who require unrestricted access to the most dangerous edges of the model’s intelligence.
The implications are staggering, and the technical trade-offs are brutal. We are witnessing the emergence of access-tiered AI, where frontier capabilities are no longer defined solely by what the model can do, but by who is asking it to do it. This is the anatomy of that rupture.
Methodology: Investigating the Mythos-Fable Architecture
This analysis was conducted through a rigorous, multi-source triangulation of primary technical documentation, official corporate announcements, and independent industry assessments. We systematically parsed Anthropic’s benchmark disclosures, cross-referenced early customer evaluations from enterprise partners (including Stripe, Replit, and CrowdStrike), and scrutinized the specific architectural routing mechanisms of the Fable 5 classifiers. Furthermore, we integrated insights from independent reporting on the national security implications of Project Glasswing, cybersecurity red-team findings, and API pricing structures to construct a holistic, verified picture of the capabilities, safeguards, and economic barriers governing this release. No claims were accepted without corroborating technical data or verified attribution.
Anthropic's Evolution: The Architecture and Training Behind Claude 5
Building on the bifurcated release mechanism detailed previously, the underlying structural reality of Claude Fable 5 and Mythos 5 is far more unorthodox than a traditional parameter scaling curve suggests. Anthropic is not presenting these systems as a conventional "small versus large" model dichotomy. Instead, they share an identical base capability level, the true "Mythos-class" foundation, differing exclusively in the embedded access controls and inferential routing architectures layered atop the base weights.
The Unified Mythos-Class Foundation
At the silicon level, there is no "Fable base model" distinct from "Mythos." The general-purpose Fable 5 wraps the exact same underlying Mythos-class capability set that powers the restricted Mythos 5, but insulates it behind a dynamic safeguard layer. When Fable 5's classifiers detect requests touching cybersecurity, biology, chemistry, or model distillation, the inference is automatically routed to Claude Opus 4.8. The user is notified of the handoff, receiving a functional but degraded response rather than a hard refusal. According to Anthropic’s launch documentation, more than 95% of Fable 5 sessions run entirely on the model's own responses without triggering this fallback.
Persistent Context and Long-Horizon Agentic Training
The leap from Opus to Mythos-class intelligence is defined not just by benchmark scores, but by sustained autonomous execution. Anthropic trained this generation to maintain focus across millions of tokens in long-running tasks, explicitly improving its outputs using its own stored notes and persistent memory. This architectural shift toward persistent file-based memory proved staggering in internal evaluations: when tasked with playing the complex deck-building game Slay the Spire, Fable 5 leveraged persistent memory to reach the game's final act three times more often than Opus 4.8, with the memory implementation improving Fable’s performance three times more than it did for the older model.
For the enterprise, this translates to AI agents that no longer suffer from context-window amnesia over multi-day workflows. As The New Stack reported, this capacity for sustained focus is precisely what allowed Stripe to compress a 50-million-line Ruby codebase migration, historically a two-month human endeavor, into a single day of autonomous compute.
Red-Teaming the Neural Tripwires
Training a classifier to reliably differentiate between a biochemist designing adeno-associated virus delivery mechanisms for gene therapy and a malicious actor seeking bioweapon uplift is a monumental technical challenge. Anthropic acknowledged that these new Fable 5 classifiers are "deliberately cautious," inevitably triggering false positives on benign requests that overlap with restricted domains. In one noted instance, Fable 5 refused to reason over its own model card simply because the document contained frequent mentions of cybersecurity and biology.
To harden the system, Anthropic subjected the classifier architecture to over 1,000 hours of external bug bounty testing. The result: zero universal jailbreaks discovered. Ars Technica further reported that external red-teaming organizations confirmed the lack of universal bypasses. One external partner found that Fable 5 complied with zero harmful single-turn cyber requests, covering exploit development, attack planning, and defense evasion, even when bombarded with 30 public jailbreak techniques. The model’s defensive robustness against automated jailbreaks now vastly outpaces previous Claude Opus iterations.
Frontier Performance by the Numbers
The training investments yield stark empirical advantages. On autonomous coding benchmarks, the Mythos architecture decimates the competition. On GDPval-AA, which measures complex analytical knowledge work, the models score 1932, vaulting past Opus 4.8 (1890) and GPT-5.5 (1769). The following data illustrates the technical gulf separating Anthropic's new tier from the previous frontier:
| Benchmark | Claude Mythos 5 | Claude Fable 5 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|---|
| SWE-bench Pro (Agentic Coding) | 80.4% | 80.3% | 69.2% | 58.6% |
| FrontierCode Diamond | 29.3% | 29.3% | 13.4% | 5.7% |
| ExploitBench (Cyber Vulnerabilities) | 78.0% | Fallback to Opus (40.0%) | 40.0% | 34.0% |
| GDPpdf (Visual Document Reasoning) | 29.8% | 29.8% | 22.5% | 24.9% |
The Compliance Overhead: 30-Day Retention
This elevated capability introduces a profound architectural friction: a mandatory 30-day data retention policy. Anthropic mandates this retention across all first-party and third-party surfaces for Fable 5, Mythos 5, and any future models of similar or higher capability. The company argues this monitoring is essential to defend against complex, multi-request attacks and to identify classifier false positives. While Anthropic pledges not to use this data for model training and promises to delete it after 30 days in almost all cases, it represents a hard line for regulated enterprises that demand strict, zero-retention data sovereignty over their proprietary prompts.
Claude Fable 5: Unpacking Capabilities, Use Cases, and Performance Metrics
While the architectural mechanics of the Mythos-to-Opus fallback system dictate the boundaries of Fable 5’s operational envelope, the practical reality of its general-use performance is where the model justifies its unprecedented $60 per million token price tag. Outside the restricted cyber and biological domains, Fable 5 does not merely edge out its predecessors; it fundamentally rewrites the economics of autonomous engineering and high-stakes knowledge work.
Autonomous Software Engineering: From Autocomplete to Migration
The defining enterprise shift is not raw code generation, but sustained, self-correcting execution. Fable 5 excels at taking on larger units of work, codebase migrations, multi-step app prototyping, and cross-tool debugging, without the constant human steering that crippled earlier models. On Cognition’s FrontierCode Diamond benchmark, which demands high-quality, maintainable agentic coding, the architecture scores 29.3% at maximum effort. Crucially, Anthropic reports that Fable 5 also tops the frontier on FrontierCode even at medium reasoning effort, suggesting the model can deliver superior results without requiring maximum compute density for every query.
This efficiency is reflected in early enterprise deployments. Cursor noted that Fable 5 "opened up a class of long-horizon problems that were out of reach for earlier models," dominating their internal CursorBench. Replit observed that the model builds apps in less time with fewer tokens on its ViBench, while Rakuten emphasized the model's capacity for self-validation: "At the highest effort, Fable 5 reflects on and validates its own work. For us, that's what makes highly autonomous operations possible."
High-Stakes Knowledge Work and Visual Reasoning
Beyond software engineering, Fable 5’s leap in persistent memory directly impacts analytical workflows where context windows previously choked model performance. On GDPpdf, a benchmark stressing visual document reasoning over messy corporate materials, spreadsheets, charts, scans, and legacy PDFs, Fable 5 scores 29.8% without tools, a significant jump over Opus 4.8 (22.5%) and GPT-5.5 (24.9%). This is the subtext of the model's design: corporate data rarely arrives in clean API endpoints. A stronger vision model allows agents to traverse unstructured visual interfaces with far less custom integration scaffolding.
The financial and legal sectors are the primary beneficiaries. Hebbia reported double-digit gains in document reasoning and problem-solving on its Finance Benchmark, while IMC found Fable 5 "aced our trading-analysis evaluations nearly across the board," excelling at root-cause and expected-value analysis. Optiver highlighted a different advantage: remarkable consistency. In repeated runs of their trading benchmark, Fable 5 scored identically, a critical metric for algorithmic reliability. In legal tech, Crosby Legal found in blind reviews that Fable 5's redlines matched or beat their current models, while Zapier noted on AutomationBench that "Where Opus stops to ask, Fable 5 keeps looking."
Vision and Agentic Interface Navigation
Anthropic also positions Fable 5 as its strongest vision model to date, capable of extracting precise numerical data from dense scientific figures and reconstructing web app source code from screenshots alone. To stress-test this visual agentic capability without relying on textual scaffolding, Anthropic placed the model in a minimal vision-only harness to play Pokémon FireRed, a game earlier Claude models failed at even with extra tools. Fable 5 successfully beat the game, demonstrating a resilient loop of environmental reading, progress memory, and long-horizon decision-making. Genspark corroborated this visual leap in enterprise contexts, ranking Fable 5 first on their evals, specifically highlighting its dominance in "UI design and game coding."
Fable 5 Enterprise Use Case Matrix
| Enterprise Domain | Core Capability Unlocked | Validating Partner / Benchmark | Operational Impact |
|---|---|---|---|
| Software Engineering | Long-horizon agentic coding, self-validation, tool-calling | Stripe, Cursor, Base44, FrontierCode Diamond | Compresses multi-month codebase migrations into days; one-shots full applications |
| Financial Analysis | Root-cause analysis, expected-value modeling, consistent repeated runs | IMC, Optiver, Balyasny, Hebbia Finance Benchmark | Replaces brittle summarization with high-stakes, deterministic analytical workflows |
| Legal & Operations | Redline generation, messy document interpretation, project planning | Crosby Legal, Notion, Zapier AutomationBench | Transforms unstructured notes into functional plans; pushes through workflow ambiguity |
| Visual Automation | UI design, game coding, legacy dashboard traversal, screenshot-to-code | Genspark, Anthropic internal testing (Pokémon FireRed) | Operates across non-API visual environments; reduces custom integration engineering |
| Data Analytics | Complex, long-running analytical tasks, chart/table extraction | Hex (Core Analytics Benchmark), GDPpdf | First model to break 90% on Hex benchmark; strong judgment on hardest queries |
Claude Mythos 5: Deep Dive into Advanced Reasoning, Logic, and Specialized Features
While Fable 5 routes high-risk inferential pathways to Opus 4.8, Mythos 5 operates without those structural diversions, unlocking the raw, dual-use cognitive tier that forced Anthropic into the access-tiered release gamble in the first place. This is not merely a model with its safety rails pulled; it is a specialized instrument engineered for domains where the safeguard itself is the primary impediment to the work.
Unleashed Cybersecurity Reasoning and Agentic Hacking
On ExploitBench, Mythos 5 achieves a 78.0% success rate on vulnerable code exploitation, a staggering 38 percentage-point leap over Opus 4.8's 40.0%, and a 9-point escalation beyond the already-restricted Mythos Preview (69.0%). But the true differentiation lies in operational fluidity. Where Fable 5 automatically neutralizes requests pertaining to vulnerability reproduction, lateral movement simulation, and defense evasion, Mythos 5 is architected to execute them sequentially.
This capacity for "agentic hacking", performing multi-part cyberattacks with autonomous reconnaissance, discovery, and exploitation, remains the core justification for Project Glasswing's existence. While Ars Technica noted that the UK’s AI Security Institute found Mythos Preview performed similarly to OpenAI’s GPT-5.5 on Capture the Flag challenges, Mythos 5 pushes the envelope further. On CyberGym, the model hits 83.8%, edging out Mythos Preview (83.1%) and decimating the fallback performance of Opus 4.8 with its default safeguards. For critical infrastructure defenders and vulnerability researchers, this transforms the model from a diagnostic tool into an autonomous red-team operative.
Computational Biology and Therapeutic Design
The biological capabilities of the Mythos class represent a vertical reasoning leap that transcends general language tasks. Anthropic’s internal protein design experts deployed Mythos 5 in a rigorous adeno-associated virus (AAV) study, a highly specific delivery mechanism used in gene therapies. Here, the model wasn't merely interpreting literature; it was actively designing therapeutics. According to Anthropic, Mythos 5 outperforms dedicated protein language models on the AAV task, accelerating parts of the drug design process by approximately tenfold.
Operating without human assistance, but equipped with protein design and bioinformatics tools, Mythos 5 matched or exceeded skilled human operators across critical workflows: choosing binding sites, selecting and running computational tools, and autonomously recovering from experimental failures. Of the 14 protein targets in the study, nine yielded strong drug design candidates now under active investigation. Furthermore, when Anthropic scientists conducted blinded comparisons between Mythos 5 and Opus-class models for novel molecular biology hypotheses, researchers preferred the Mythos 5 hypotheses roughly 80% of the time. The Wall Street Journal highlighted that these biological capabilities were central to Anthropic's decision to restrict the model, as the same reasoning that designs gene therapies can theoretically pathogenize biological threats.
Independent Corroboration and the "E. coli" Hypothesis
Perhaps the most striking validation of Mythos 5’s advanced multidisciplinary reasoning is its capacity for independent scientific discovery. During the protein design evaluations, Mythos 5 generated a novel hypothesis involving an E. coli protein. Crucially, this AI-generated hypothesis was later corroborated by an independent laboratory working on the exact same problem, a milestone that elevates the model from a high-speed literature synthesizer to a potential wellspring of de facto scientific discovery. While Anthropic intends to publish detailed results in the coming months, the directional implication is severe: frontier AI models are now capable of producing testable, empirically validated biological insights that escape the reasoning constraints of their predecessors.
| Domain | Task / Capability | Mythos 5 Performance | Operational Significance |
|---|---|---|---|
| Cybersecurity (Exploitation) | Vulnerability discovery, agentic hacking, exploit development | 78.0% (ExploitBench) / 83.8% (CyberGym) | Enables autonomous red-teaming and multi-stage attack simulation; bypasses the Opus 4.8 fallback enforced on Fable 5. |
| Computational Biology | AAV gene therapy delivery design, protein target selection | Outperforms dedicated protein LLMs; 10x acceleration in drug design phases | Matches skilled human operators; 9 of 14 targets produced strong drug candidates without human intervention. |
| Molecular Hypothesis Generation | Novel scientific inference, experimental design | Preferred over Opus hypotheses 80% of the time in blind reviews | One E. coli protein hypothesis independently corroborated by an external lab. |
The Geopolitics of Trusted Access
The logic of Mythos 5’s restricted availability is inextricable from geopolitical reality. Following the debut of Project Glasswing and the Mythos Preview, U.S. officials and intelligence agencies began analyzing how such models could reshape global cyber operations, prompting Sen. Mark Warner to warn that AI-assisted vulnerability discovery should force the industry to "accelerate and reprioritize patching." The regulatory reverberations extended to the financial sector, where The Guardian reported that Mythos entered discussions among senior U.S. and U.K. banking officials fearful of AI-accelerated threats to payment systems.
But fear is only half the equation; demand is the other. Reuters reported that South Korea’s national internet security agency secured Mythos access through Project Glasswing, reflecting a broader geopolitical race to harness frontier AI for national cyber defense. Anthropic plans to expand Mythos 5 access through a more systematic trusted-access program, developed in consultation with the U.S. government. For life sciences organizations, a separate access path is emerging that will lift the biology and chemistry safeguards while maintaining the cybersecurity restrictions, allowing vetted researchers to traverse the high-risk molecular design workflows that Fable 5 automatically severs.
The Gatekeeper's Dilemma
Anthropic’s position as the arbiter of who gets to wield this level of advanced reasoning is not without friction. The Verge reported that unauthorized users accessed Mythos during its limited rollout, a damaging breach for a company staking its brand on responsible AI. Furthermore, critics have questioned whether Anthropic’s warning-heavy framing functions as a form of market positioning, conveniently casting the company as both the creator of the world's most dangerous dual-use AI and the sole gatekeeper authorized to distribute it. With Mythos 5, the gatekeeping is formalized: the most advanced reasoning on the planet is available only to those Anthropic and its government partners deem trustworthy enough to wield it without destabilizing the systems it was designed to protect.
Claude Fable 5 vs. Claude Mythos 5: A Comparative Analysis of AI Paradigms
Moving beyond the isolated performance metrics of each system, the true architectural divergence between Fable 5 and Mythos 5 reveals a fundamental restructuring of how frontier AI capability is packaged, governed, and monetized. This is not a traditional tiered deployment based on parameter count or inference speed; it is a dynamic, intent-based routing paradigm where the model's ultimate output is dictated by the trust level of the user and the semantic classification of the prompt.
The Intent-Based Routing Chasm
Because the base weights are identical, the comparative analysis distills entirely into the behavior of Fable 5’s classifier system versus Mythos 5’s unmitigated inference engine. Fable 5 operates as a conditional model, dynamically downgrading its own cognitive capacity when its neural tripwires detect semantic proximity to cybersecurity, biology, chemistry, or distillation vectors. The cost of this conditional architecture is an unavoidable latency and capability penalty on the fringes of legitimate enterprise work. Security professionals, biochemists, and advanced researchers operating within the 5% fallback zone experience not a smarter model, but a deliberately crippled one, rerouted to Opus 4.8’s inferior reasoning loops. Mythos 5 exists precisely to eliminate this friction for vetted entities, providing unbroken, state-of-the-art inferential depth across the entire dual-use spectrum.
| Architectural Dimension | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
| Base Model Identity | Mythos-class foundation | Mythos-class foundation |
| Inference Routing | Conditional; downgrades to Opus 4.8 upon classifier detection of high-risk domains | Unmitigated; maintains maximum inferential depth across all query types |
| Distillation Resistance | Active; blocks and reroutes model distillation and extraction attempts | Permissive for approved institutional research; unblocked for trusted users |
| Agentic Hacking Capability | Neutralized; reconnaissance and lateral movement queries severed | Unleashed; autonomous multi-stage attack simulation fully operational |
| Bio/Chem Reasoning | Hard-stopped; reroutes molecular design and protein engineering queries | Unrestricted; outperforms dedicated protein LLMs and generates novel hypotheses |
| Access Mechanism | Open API and Consumer Subscriptions (with temporary capacity constraints) | Project Glasswing and U.S. Government-consulted trusted access programs |
Commercial Efficacy vs. Specialized Lethality
For CTOs and enterprise architects, the comparative value proposition hinges on workflow alignment. Fable 5 is optimized for commercial efficacy, specifically, the execution of long-horizon, high-complexity tasks in software engineering, financial analysis, and legal operations where the operational domain safely avoids the restricted categories. It is a high-yield commercial engine. Mythos 5, conversely, is optimized for specialized lethality and therapeutic discovery. Its unmatched utility lies precisely in the territories Fable 5 abandons: simulating advanced cyberattacks, mapping vulnerabilities in critical infrastructure, and performing autonomous computational biology. The models are not competitors; they are complementary instruments designed to prevent the commercial mainstream from accessing the destructive ceiling of their shared architecture.
The Economic Paradox of Identical Pricing
The most striking comparative anomaly is economic. Anthropic prices both Fable 5 and Mythos 5 identically at $10 per million input tokens and $50 per million output tokens. This parity defies traditional SaaS logic, where restricted, high-security products typically command massive premiums over general-purpose counterparts. Instead, the premium is embedded in the access barrier, not the API cost. The exorbitant $60 total cost per million tokens, twice the price of Opus 4.8 and up to 100% higher than OpenAI’s GPT-5.5, acts as a blunt instrument to throttle trivial usage, ensuring that only high-margin enterprise workflows or state-backed defense programs can sustain the compute burn of a Mythos-class engine. You are not paying more for Mythos 5’s unshackled capabilities; you are paying the same astronomical rate for the privilege of not being downgraded.
Enterprise Integration: API, Pricing, and Deployment Strategies for Claude 5 Models
Translating the bifurcated Mythos-class architecture into viable enterprise infrastructure requires navigating a deployment landscape defined by aggressive token economics, forced capacity constraints, and strict compliance overlays. Building on the identical $10 per million input and $50 per million output token pricing structure detailed previously, the operational reality of integrating these models demands acute architectural foresight.
API Routing and Multi-Cloud Availability
For developers, Fable 5 is accessible via the Claude API under the designated identifier claude-fable-5. Anthropic has broadened the deployment footprint beyond its proprietary endpoints, making the model available on major cloud AI platforms including Microsoft Foundry, Amazon Bedrock, and the Claude Platform on AWS. This multi-cloud availability is critical for enterprise architects who require vendor-agnostic infrastructure and private VPC integration to satisfy data sovereignty requirements, particularly given the mandatory 30-day retention policy.
The Subscription Capacity Crunch
While API and consumption-based Enterprise plans enjoy immediate, unrestricted access, the subscription tier rollout is uniquely volatile. Anthropic has implemented a hard cutoff strategy to manage inferencing demand: from launch through June 22, Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost. On June 23, Anthropic will remove Fable 5 from those subscription tiers entirely, forcing users to purchase usage credits to maintain access. The company claims it aims to restore Fable 5 as a standard subscription feature once "sufficient capacity" allows, but the timeline remains undefined. For engineering leads, this means building critical agentic workflows on a foundation that may suddenly incur unpredictable, unbudgeted per-token costs mid-quarter.
Frontier API Pricing Context
The $60 aggregate cost per million tokens positions the Claude 5 family as the most expensive mainstream AI model on the market. To contextualize this economic friction against the broader frontier model landscape, enterprise architects must weigh raw capability against token drain:
| Model | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Total Aggregate Cost |
|---|---|---|---|
| Xiaomi MiMo-V2.5 Flash | $0.10 | $0.30 | $0.40 |
| DeepSeek v4 Pro | $0.435 | $0.87 | $1.305 |
| Google Gemini 3.5 Flash | $1.50 | $9.00 | $10.50 |
| OpenAI GPT-5.4 | $2.50 | $15.00 | $17.50 |
| OpenAI GPT-5.5 | $5.00 | $30.00 | $35.00 |
| Anthropic Claude Opus 4.8 | $5.00 | $25.00 | $30.00 |
| Anthropic Claude Fable 5 / Mythos 5 | $10.00 | $50.00 | $60.00 |
Strategic Deployment and Failover Architecture
Because Fable 5 seamlessly degrades to Opus 4.8 when its classifiers trigger, enterprise deployment strategies must account for a dual-model inferencing environment. If an agentic workflow strays into a restricted domain, such as a code migration tool inadvertently analyzing a proprietary cryptography library, the system automatically falls back to Opus 4.8's inferior reasoning capacity. Architects must design routing logic that anticipates this capability drop, implementing human-in-the-loop breakouts for high-stakes tasks that risk classifier activation.
Furthermore, while Fable 5 is designed to require less scaffolding than its predecessors, as demonstrated by its ability to navigate visual environments with a minimal harness, the token economics of sustained autonomous operation are punishing. A model that can independently execute a multi-day codebase migration or traverse a 50-million-line Ruby repository burns through tokens at a rate that invalidates traditional LLM cost projections. The true cost of Fable 5 is not merely the price of the prompt, but the compute density required to let the model "keep looking" until the task is done.
The Data Sovereignty Trade-Off
Finally, the mandatory 30-day retention policy acts as an active deployment filter. Regulated entities, banks managing trading algorithms, healthcare organizations processing proprietary patient data, and legal firms handling privileged communications, must now weigh Fable 5's unprecedented analytical capabilities against the strict reality that their prompts and outputs will reside on Anthropic's servers for a month. As The New Stack highlighted, some enterprises will flatly refuse to opt into this data storage, forcing a regression to Opus 4.8 or competitor models. For organizations that can absorb the retention risk, the integration payoff is autonomous engineering at an unprecedented scale. For those that cannot, the Mythos-class capability remains functionally out of reach.
Safety and Alignment: Anthropic's Constitutional AI in the Claude 5 Era
Building on the intent-based routing mechanisms and external red-team validations detailed previously, Anthropic’s actualization of safety in the Claude 5 era represents a radical departure from static refusal architectures. Constitutional AI, the methodology where models are trained to critique and revise their own outputs based on a predefined set of principles, has evolved from a behavioral guardrail into a dynamic, inferential switching system. Fable 5 does not simply "refuse" dangerous queries; it structurally demotes its own cognitive capacity in real-time, a feat of alignment engineering that introduces unprecedented complexities in model predictability and user trust.
The Classifier-Driven Constitutional Bifurcation
In previous Claude generations, Constitutional AI operated as a post-hoc filter: the model generated a response, evaluated it against constitutional principles, and either delivered it or issued a hard refusal. Fable 5 abolishes this binary. Instead, the constitutional framework is embedded directly into the pre-inference routing layer. When the model's classifiers detect semantic proximity to restricted domains, cybersecurity, biology, chemistry, or distillation, the constitution dictates an architectural handoff to Opus 4.8. The user is not met with a wall of refusal, but a functional, degraded response from an older paradigm. This is alignment as a dynamic capability throttle, not a stop sign.
However, this architectural leap introduces a severe alignment challenge: classifier brittleness. As noted in early testing, Fable 5’s constitutional tripwires are tuned with such aggressive caution that they trigger on benign context. The model refusing to parse its own model card because the text contained the words "cybersecurity" and "biology" demonstrates a semantic overfitting problem. The constitution is effectively blacklisting conceptual categories rather than evaluating specific malicious intent, leaving legitimate researchers and enterprise users navigating a minefield of false positives.
The "Uplift" Doctrine and Asymmetric Risk Modeling
Anthropic’s constitutional logic for the Mythos class now hinges entirely on the doctrine of "uplift", the metric of how much a model accelerates a malicious actor's ability to cause harm compared to existing tools. According to Ars Technica, Anthropic justifies the sweeping biology and chemistry blocks on Fable 5 by asserting that "well-resourced malicious actors" could use seemingly benign queries to achieve "highly risky biological research" far more effectively than with previous models. The constitutional principle has shifted from preventing explicit harm to preventing asymmetric capability acceleration.
This preemptive alignment strategy creates a paradoxical trust dynamic. Anthropic has essentially conceded that the model is too competent at certain reasoning tasks to be trusted with the general public. As ZDNet observed, Fable 5 is a "defanged" iteration of Mythos, a formulation that highlights the core tension of Anthropic's safety positioning. If the model requires surgical incapacitation to be safe for commercial release, the reliability of its unrestricted state remains an open, existential question for regulators.
Jailbreak Resistance vs. Constitutional Rigidity
The empirical success of Fable 5’s alignment lies in its defensive robustness, but the cost of that robustness is operational inflexibility. The external bug bounty and red-team findings, zero universal jailbreaks across 1,000+ hours, and compliance with zero harmful single-turn cyber requests even under 30 public jailbreak techniques, represent a major triumph for adversarial defense. Yet, this impenetrability is achieved through broad semantic exclusion. The constitutional AI is not engaging in nuanced ethical reasoning; it is executing a rigid, high-recall classification filter.
| Alignment Paradigm | Previous Claude Generations | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|---|
| Core Safety Mechanism | Post-hoc self-critique and hard refusal | Pre-inference semantic classification and architectural routing | Contextual trust-boundary execution |
| Handling High-Risk Queries | Hard refusal; user blocked | Dynamic fallback to Opus 4.8; user notified but not blocked | Full inferential execution for vetted users |
| Alignment Philosophy | Prevent generation of harmful content | Prevent asymmetric "uplift" of malicious actors | Assume user vetting replaces model-level guardrails |
| Primary Failure Mode | Jailbreak via prompt manipulation | False positives; semantic over-triggering on benign context | Human trust boundary violation; insider threat |
Trust as the Ultimate Alignment Layer
With Mythos 5, Anthropic concedes a critical philosophical point: for a sufficiently capable model, algorithmic alignment eventually reaches its limit, and human trust must become the final safeguard. As The Wall Street Journal reported, the release mechanism relies on removing dangerous capabilities for the general public while granting them exclusively to approved entities. The constitutional AI of Mythos 5 is not embedded in the model's weights; it is outsourced to the vetting procedures of Project Glasswing and the U.S. government-consulted trusted access programs.
This bifurcation redefines the future of AI safety. For the commercial mainstream, alignment means living inside an algorithmic straitjacket where the model proactively dimishes its own intelligence to stay within safe bounds. For the anointed few, alignment means operational accountability, the model serves its full destructive potential, and the safety guarantee is the human clearance holding the API key. It is an honest, if unsettling, architectural acknowledgment: at the frontier of artificial intelligence, the only reliable safeguard against a model that can autonomously hack critical infrastructure or design novel pathogens is ensuring the person asking it to do so has the proper security clearance.
Market Impact: How Claude Fable 5 and Mythos 5 Compete with GPT-5 and Gemini
Building on the economic friction of the $60 aggregate token cost and the philosophical realignment of safety paradigms, Anthropic’s market positioning with the Claude 5 family is a deliberate assault on the baseline assumptions of the frontier AI sector. By introducing an access-tiered, intent-routed architecture, Anthropic is not just competing on benchmark curves against OpenAI’s GPT-5.5 and Google’s Gemini 3.1 Pro; it is attempting to redefine the unit of competition itself; from raw capability per dollar to autonomous reliability per risk.
The Agentic Coding Supremacy vs. The Cost Center
The most immediate competitive shockwave is in autonomous software engineering, where Mythos-class models threaten to invalidate the current GPT-5 and Gemini deployment paradigms. The SWE-bench Pro chasm, Fable 5 at 80.3% versus GPT-5.5 at 58.6% and Gemini 3.1 Pro at 54.2%, is not a marginal leaderboard flex. It is a structural inflection point. At below 60%, AI coding assistants are expensive co-pilots requiring constant human debugging and verification. Above 80%, they become viable autonomous operators capable of executing multi-day migrations without human intervention. Stripe’s one-day, 50-million-line Ruby migration proves the economic math: a model that operates independently at an exorbitant per-token rate is vastly cheaper than a cheaper model that stalls, hallucinates, and demands constant engineering correction.
However, this supremacy carries a toxic margin risk. Because Fable 5 can "keep looking" and self-correct through ambiguity, its token consumption during sustained agentic workflows is fundamentally unbounded. OpenAI and Google can compete on volume, offering models like Gemini 3.5 Flash at a $10.50 total aggregate cost for low-stakes, high-throughput tasks. For enterprise CTOs, the emerging architecture is bifurcated: cheap, fast models for routine code completion, and Fable 5 reserved strictly for high-complexity, long-horizon operations where the cost of failure outweighs the compute burn.
The Enterprise Knowledge Work Siege
In the domain of high-stakes analytical reasoning, Fable 5 directly challenges GPT-5.5’s dominance in the financial and legal sectors. The GDPval-AA scores (1932 for Fable 5 vs. 1769 for GPT-5.5) translate to a tangible operational leap: fewer correction loops, higher accuracy in visual document reasoning, and deterministic consistency across repeated runs. Optiver’s observation that Fable 5 scored identically across repeated trading benchmark runs is a direct shot at Google and OpenAI’s enterprise positioning. In algorithmic trading and legal redlining, variance is a liability. Fable 5’s consistency makes it the first frontier model suitable for regulated, deterministic workflows where GPT-5.5’s variance remains a compliance risk.
Competitive Landscape Matrix: Claude vs. The Frontier
| Competitive Dimension | Anthropic (Claude Fable 5 / Mythos 5) | OpenAI (GPT-5.5) | Google (Gemini 3.1 Pro) |
|---|---|---|---|
| Agentic Coding (SWE-bench Pro) | 80.3% / 80.4% | 58.6% | 54.2% |
| Knowledge Work (GDPval-AA) | 1932 | 1769 | 1314 |
| Visual Document Reasoning (GDPpdf) | 29.8% | 24.9% | 16.7% |
| Cybersecurity Capability (ExploitBench) | Fallback (40%) / 78.0% (Mythos) | 34.0% | N/A (Not specialized) |
| API Cost (Total Aggregate per 1M tokens) | $60.00 | $35.00 | $22.00 (>200K context) |
| Safety Architecture | Intent-based routing; dynamic capability downgrade | Post-hoc refusal; standard RLHF | Standard refusal filters; systemic safety |
| Data Retention Policy | Mandatory 30-day retention | Variable; zero-retention enterprise tiers available | Variable; zero-retention enterprise tiers available |
The Cybersecurity Moat and the Trusted Access Monopoly
The most insurmountable competitive moat Anthropic has constructed is not in general coding, but in dual-use cyber and biological reasoning. Neither GPT-5.5 nor Gemini 3.1 Pro currently offers a commercially validated, state-backed pathway for unrestricted vulnerability exploitation and agentic hacking. By monopolizing the Mythos 5 distribution through Project Glasswing and U.S. government-consulted trusted access, Anthropic has effectively cornered the market on AI-assisted national cyber defense.
While Ars Technica noted that the UK’s AI Security Institute found Mythos Preview performed similarly to GPT-5.5 on Capture the Flag challenges, Mythos 5’s 78.0% on ExploitBench shatters that parity. This creates a geopolitical vendor lock-in: intelligence agencies and critical infrastructure defenders cannot achieve equivalent offensive simulation capabilities through OpenAI or Google APIs. Anthropic is no longer just selling compute; it is selling sovereign cyber capability, gating it behind a proprietary clearance mechanism that competitors cannot easily replicate.
The Data Sovereignty Vulnerability
Anthropic’s competitive vulnerability lies in its mandatory data retention policy. While Fable 5 outperforms GPT-5.5 and Gemini on document and analytical benchmarks, the forced 30-day logging requirement is a severe enterprise friction point. OpenAI and Google have aggressively pursued zero-retention architectures for regulated sectors, banking, healthcare, and legal, specifically to capture workloads involving proprietary algorithms and privileged data. Anthropic’s argument that retention is essential for monitoring "complex and novel attacks" is structurally sound, but commercially penetrable. Competitors will weaponize this policy, offering slightly less capable models that guarantee zero data persistence to regulated buyers who prioritize data sovereignty over a 10-point benchmark advantage. Anthropic is betting that the delta in autonomous reliability outweighs the compliance overhead; the market will determine if that bet holds.
Methodology: Market Positioning Analysis
This competitive analysis was constructed by triangulating publicly disclosed benchmark data from Anthropic’s launch materials against independent industry pricing indexes and confirmed enterprise deployment case studies. We evaluated not only the raw performance deltas on SWE-bench Pro, GDPval-AA, and ExploitBench, but also the structural unit economics of sustained agentic operation, factoring in token burn rates during long-horizon tasks. Competitor positioning was assessed through a comparative lens of API pricing architectures, safety paradigms (post-hoc refusal vs. intent-based routing), and enterprise data retention policies. Furthermore, the geopolitical market implications of Project Glasswing were analyzed in the context of national cyber defense procurement strategies, drawing on verified reporting of international agency access and regulatory responses to Mythos-class capabilities.
The Future of AI: Predictions and Roadmaps for the Claude Ecosystem
Building on the access-tiered architecture and competitive market fractures detailed previously, the trajectory of the Claude ecosystem points toward a fundamental restructuring of how frontier AI is governed, scaled, and integrated into sovereign infrastructure. The Fable/Mythos bifurcation is not a static product launch; it is a live prototype for a new regulatory-compute paradigm. If Anthropic’s intent-based routing holds under real-world enterprise strain, it will become the de facto blueprint for releasing superintelligent systems without triggering a dual-use catastrophe.
The Inevitable Expansion of the Trusted Access Paradigm
Project Glasswing is currently a restricted enclave for cyber defenders and a handful of elite biology researchers, but the roadmap inevitably points toward a segmented, multi-domain trust matrix. Anthropic has already signaled that it plans to expand Mythos 5 access "in consultation with the U.S. government," but the structural demand will force a modular unblocking of specific verticals. The emerging life sciences trusted-access program, which lifts biological and chemical safeguards while maintaining cybersecurity restrictions, proves that Anthropic views trust not as a binary gate, but as a granular, domain-specific dial. We can predict the emergence of tailored Mythos 5 access tiers: a "Cyber-Offense" clearance for red-team agencies, a "Therapeutic Design" clearance for pharmaceutical giants, and inevitably, a "Quantum-Materials" clearance for advanced physics and semiconductor research. The gatekeeper state will expand.
The False Positive Correction and the "Shadow Opus" Problem
Fable 5’s current constitutional rigidity, where the model refuses to parse its own model card due to semantic over-triggering, is an acknowledged bug, not a permanent feature. Anthropic has stated its intent to reduce false positives over time. However, the roadmap for refining these classifiers carries a severe architectural risk: as the sensitivity dials down to allow benign biology and cybersecurity queries through, the attack surface for adversarial jailbreaks expands proportionally. The future of the Claude ecosystem will be defined by an invisible arms race between classifier nuance and adversarial prompt camouflage. Furthermore, because Fable 5 seamlessly degrades to Opus 4.8, enterprises will begin mapping the exact semantic boundaries of the fallback triggers. Sophisticated developers will learn to architect their agentic workflows to avoid the "Shadow Opus" penalty, steering prompts just clear of the tripwires to maintain Mythos-class inference, effectively weaponizing the classifier map against itself.
Predicted Claude Ecosystem Milestones
| Timeframe | Predicted Development | Enterprise & Geopolitical Impact |
|---|---|---|
| Q3-Q4 2026 | Restoration of Fable 5 to standard subscription tiers; capacity stabilization. | Unpredictable per-token credit costs subside; agentic workflow budgeting becomes viable for mid-market teams. |
| Late 2026 | Launch of formalized, multi-domain Trusted Access Programs (TAP) beyond Project Glasswing. | Pharmaceutical and materials science firms gain restricted Mythos 5 access; sovereign cyber defense alliances solidify around Anthropic's API. |
| 2027 | Release of granular classifier controls for enterprise API deployments. | CTOs gain limited ability to adjust fallback thresholds based on internal compliance, reducing the "Shadow Opus" friction in specialized verticals. |
| 2027-2028 | Phase-out of the Opus tier as the primary commercial flagship. | Mythos-class becomes the new baseline; a yet-unseen, higher capability tier (speculated "Epic" class) necessitates an even stricter global gating apparatus. |
Data Sovereignty Concessions and the Zero-Retention Frontier
The mandatory 30-day retention policy is currently Anthropic’s biggest commercial Achilles' heel. As competitors weaponize zero-retention architectures to capture regulated enterprise workloads, the Claude roadmap must inevitably yield to market pressure. We predict the introduction of highly premium, isolated "Sovereign Fable" deployments, likely through AWS or Microsoft Foundry private VPCs, where the 30-day retention requirement is waived for enterprises willing to pay extreme premiums and assume full liability for adversarial monitoring. Anthropic cannot afford to permanently cede the financial, legal, and healthcare sectors to OpenAI and Google over a data-logging mandate. The retention policy will shift from a blanket rule to a negotiated, risk-assumed enterprise feature.
The Successor Paradigm: Beyond Fable and Mythos
The Fable/Mythos naming convention, drawing on Britannica’s definitions of a "moral story" versus a "complex body of sacred narratives", suggests a structured linguistic hierarchy for future models. If Fable is the safeguarded public iteration and Mythos is the restricted, dual-use truth, the next capability plateau will likely demand a new lexical tier. We project the eventual arrival of an "Epic" class or similar nomenclature, representing models with autonomous, cross-domain scientific execution capabilities that even the Glasswing partners cannot access without real-time, active governmental oversight. The Claude ecosystem is evolving from a software service into a critical infrastructure utility, and the roadmaps will reflect not just technical scaling, but the geopolitical containment protocols required to deploy it.



Comments
Leave a Comment
Your comment will appear after moderation.